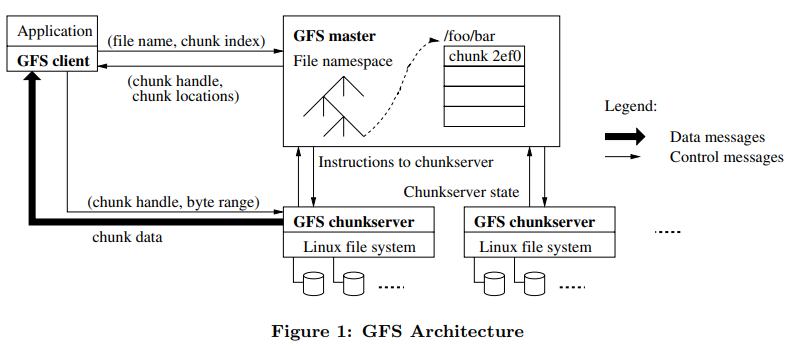
pgmoneta is a backup / restore solution for PostgreSQL. The existing codebase already contains some encryption code used to encrypt passwords. I enhanced the encryption API, created new encryption workflow, and added cli options so that the encryption can be applied to wal and other data (e.g. config file). The documentation and benchmarking test are also provided for users to reference.
Contribution
Early Stage Investigation and Code Refactoring
At early stage, we discussed what encryption algorithms should be supported. As result, AES CBC mode and AES CTR mode are choosed for following reasons:
Advanced Encryption Standard Instruction Set (AES-NI) is now integrated into many processors. Hardware acceleration made AES outperform other algorithms.
CBC is supported because it is the most commonly used and considered save mode. Its main drawbacks are that encryption is sequential (decryption can be parallelized).
CTR is supported because both encryption and decryption are parallelizable. We offer user a faster encrtypt option.
After determining what algorithms to support, I moved existing aes code from security.h(c) to aes.h(c) before implement the feature.
Feature Implemention
Commits are squashed into one single pull request and you can check it here.
This is the most challenging part of the GSoC event. I spent lots of time understanding how the current event loop and workflow work. Debugging a multi-process program is a painful but fun experience and I learned a lot about gdb and addresssanitizer. Another challenge is handling complicated git workflow. I was always afraid to accidentally lose my changes when dealing with git. Participating GSoC and interacting with other people made me have a better understanding of git workflow.
Documentation and Benchmarking
The encryption feature is well documented. The configuration file parameter and its available options are listed in doc/CONFIGURATION.md. The comparison and choose of AES modes are described ENCRYPTION.md. The tutorial of perform a benchmarking test and test result also documented in ENCRYPTION.md.
Transaction(): start ts(oracle.GetTimestamp()){} voidSet(Write w){ writes.push back(w); } boolGet(Row row, Column c, string * value){ while (true) { bigtable::Txn T = bigtable::StartRowTransaction(row); // Check for locks that signal concurrent writes. if (T.Read(row, c + "lock", [0, start ts])) { // There is a pending lock; try to clean it and wait BackoffAndMaybeCleanupLock(row, c); continue; }
// Find the latest write below our start timestamp. latest write = T.Read(row, c + "write", [0, start ts]); if (!latest write.found()) returnfalse; // no data int data ts = latest write.start timestamp(); * value = T.Read(row, c + "data", [data ts, data ts]); returntrue; } } // Prewrite tries to lock cell w, returning false in case of conflict. boolPrewrite(Write w, Write primary){ Column c = w.col; bigtable::Txn T = bigtable::StartRowTransaction(w.row);
// Abort on writes after our start timestamp . . . if (T.Read(w.row, c + "write", [start ts, ∞])) returnfalse; // . . . or locks at any timestamp. if (T.Read(w.row, c + "lock", [0, ∞])) returnfalse;
T.Write(w.row, c + "data", start ts, w.value); T.Write(w.row, c + "lock", start ts, { primary.row, primary.col }); // The primary’s location. return T.Commit(); } boolCommit(){ Write primary = writes[0]; vector < Write > secondaries(writes.begin() + 1, writes.end()); if (!Prewrite(primary, primary)) returnfalse; for (Write w: secondaries) if (!Prewrite(w, primary)) returnfalse;
int commit ts = oracle.GetTimestamp();
// Commit primary first. Write p = primary; bigtable::Txn T = bigtable::StartRowTransaction(p.row); if (!T.Read(p.row, p.col + "lock", [start ts, start ts])) returnfalse; // aborted while working T.Write(p.row, p.col + "write", commit ts, start ts); // Pointer to data written at start ts . T.Erase(p.row, p.col + "lock", commit ts); if (!T.Commit()) returnfalse; // commit point
// Second phase: write out write records for secondary cells. for (Write w: secondaries) { bigtable::Write(w.row, w.col + "write", commit ts, start ts); bigtable::Erase(w.row, w.col + "lock", commit ts); } returntrue; } } // class Transaction
“Edsger W. Dijkstra Prize in Distributed Computing” by PODC Dijkstra賞は2000から、分散システム分野に物凄く影響ある論文に授与する賞である。よく耳にするLamport Clock[18]、Global Snapshot[19]、FLP Impossibilityから、分散システムの基盤理論となったWait-Free[20]、Lock-Free[21]、Liveness Property[22] まで多く収録されている。これらの論文を読んで、基礎理論を深く理解し、今までどんな研究したか、どんな成果が出たかを知る。これからの研究には不可欠であることと考えている。 CS294-91 Distributed Computing UC Berkeley大学が主催し、基礎理論に注目したオープン講座である。扱う参考書や論文、授業中のスライドなどのリソースがある。これをガイドラインとして、理論知識の学習を進めると考えている。
論理の実装及び応用をみる
“The Hall of Fame Award” by ACM SIGOPS HOFはOS分野の賞であるが、分散システムに関する論文も多く授与している。Dijkstra賞は理論的なものがメインで、HOFはエンジニアリング、実際な実装を注目している。例としてDynamoやBigtableなどが収録されている。これらの論文を読んで、ケーススタディーとして、分散システムに関する理論がどういう風に応用されているかを知ることができると考えている。また、実装から妥結した設計や、不満点などを探って、「それをどうやって改善しようか」とのことがこれからの研究方向にもなると考えている。
6.824: Distributed Systems MIT大学のオープン講座である。レクチャーは生産環境で大規模に応用されるシステムについての論文の読み及び説明を中心とした。レクチャーの録画まであるので、ケーススタディーの理解を深めるやスピードアップに助かるリソースになると思う。
以上の2段階を乗り越えると、分散システム分野において、全体的な知識や研究内容について把握できると考える。それから先行研究を把握したうえで研究することを目標にして、 自分に興味があったテーマを選び、よりに範囲を絞って、テーマに関する論文や教科書を洗い出して学習する。先行研究の研究手法や結論などをまとめて、文献レビューを作成する。されに、先行研究から研究不足やまだやってないことを探して、自分の研究を決める。そこから具体的な研究手法を考えて、研究を進めていく段階になるが、今はテーマが決まっていないため詳細な計画を立つことはできない状態である。しかし、その時研究を順調にできるために、あらかじめ研究メソッドについての学習はできると考える。学習材として、COMP516 Research Methods in Computer Science (2007-2008)リバプール大学からのオープン講座があり、これを入学前にオンライン履修して、入学後の研究生活をスムーズにいけると考える。 また、先生が研究テーマを指示した場合は、そちらのテーマで研究を行うと考えている。
classSolution { public: intmaxProfit(vector<int>& prices, int fee){ int res = 0, min = prices[0]; for(int i = 0; i < prices.size(); ++i) { if(prices[i] < min) min = prices[i]; if(prices[i] > min + fee) { res += prices[i] - min - fee; min = prices[i] - fee; } } return res; } };